Nel Corso del 2021 si sentono continuamente ricercatori di security che analizzano e parlano di svariate CVE (Common Vulnerabilities and Exposures) facenti riferimento a moltissimi malcapitati Web Server. Andando a spulciare meglio questi articoli troverete molto spesso riferimenti al protocollo ‘HTTP’, questo malcapitato viene sfruttato ingiustamente per proxare verso i backend con metodi non propriamente simpatici dai nostri amici “LoHacker” o “LoCracker”.
La tipologia di attacco più diffusa che leggerete in giro è l’SFFR (Server-Side Forgery Request), tradotto letteralmente in “Falsificazione della richiesta lato Server”.
Ma che tipologia di attacco è? E cosa significa falsificazione della richiesta lato Server?
SSRF è un tipo di vulnerabilità presente nelle applicazioni Web, tramite questa vulnerabilità un utente malintenzionato (“LoHacker” o “LoCracker”) può effettuare ulteriori richieste HTTP attraverso il Web Server. Un utente malintenzionato può sfruttare questa vulnerabilità per comunicare con eventuali servizi interni sulla rete delle macchine che espongono i servizi Backend, generalmente protetti da firewall (ci si auspica almeno questo).
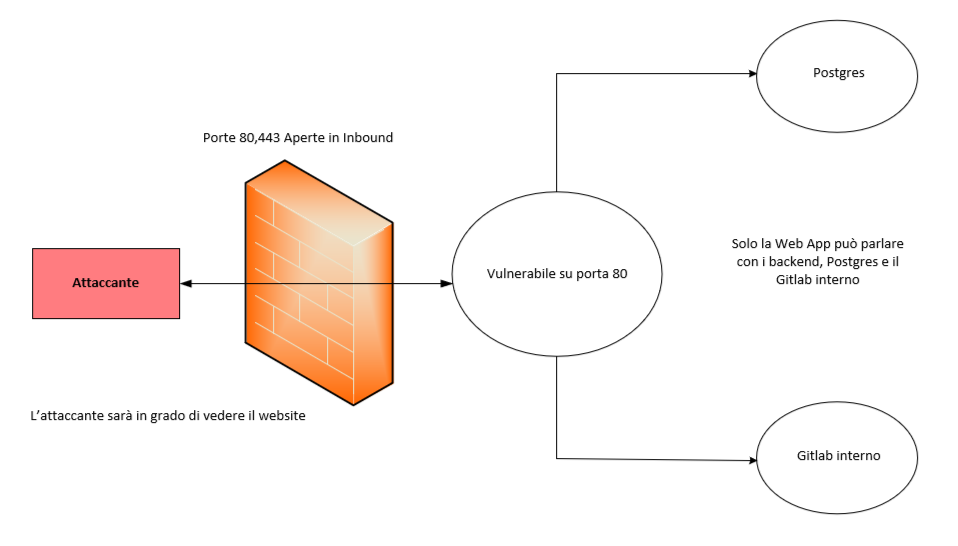
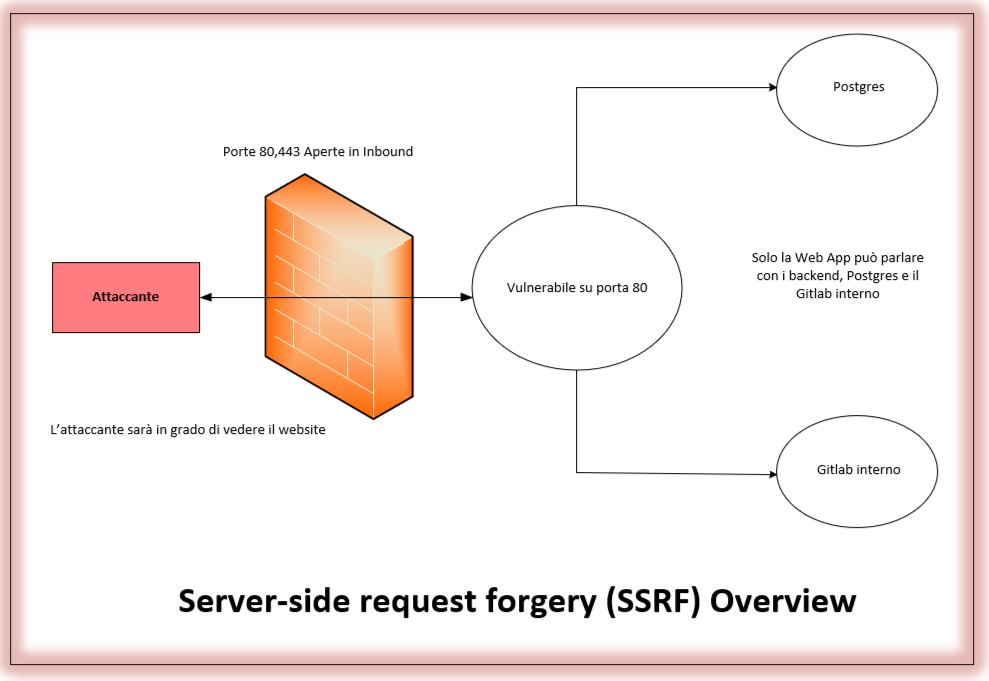
Figura 1 – Diagramma Esempio attacco SSRF
Ora se ci concentriamo sul diagramma soprastante, in un caso normale (per normale vogliamo parlare di un caso in cui abbiamo fatto quella cosa che ci dà tanto noia, IL PATCHING) l’attaccante sarebbe solo in grado di visitare il Web Site e di vedere solo ciò che il Web Site gli espone. La macchina con a bordo il Web Server è autorizzata a comunicare con il Postgress o il Gitlab interno, ma chiaramente l’utente finale non può, perché il firewall di frontiera consente solo l’accesso alle porte 80 (HTTP) e 443 (HTTPS). Tuttavia, SSRF (Server-Side Request Forgery) darà al malintenzionato il potere di stabilire una connessione a Postgres e vedere i suoi dati connettendosi prima al server del Web Site esposto in HTTP/HTTPS, per poi utilizzarlo successivamente per collegarsi al database. In questo scenario Postgres penserà che il sito Web stia richiedendo qualcosa di lecito dal database, ma in realtà è l’attaccante che utilizza una vulnerabilità SSRF nel Web Site per ottenere i dati.
Il processo dell’utilizzo di questa vulnerabilità solitamente è simile a questo:
- Un utente malintenzionato trova una vulnerabilità SSRF su un Web Site.
- Il firewall consente tutte le richieste al sito esposto dal Web Server.
- L’attaccante sfrutta quindi la vulnerabilità SSRF costringendo il web server a richiedere dati dal database, che poi restituisce all’attaccante. Poiché la richiesta proviene dal web server, anziché direttamente dall’attaccante, il firewall consente il passaggio.
Quali sono le cause di questa vulnerabilità?
Abbiamo quindi capito che cos’è SSRF, ora vediamo più nel dettaglio a causa di quali errori i Web Site diventano vulnerabili a SSRF.
La causa principale dell’esposizione a questa tipologia di attacco è (come accade spesso anche in altri ambiti), il fidarsi ciecamente nella tipologia di richiesta che l’utente farà al Frontend del vostro web server (si purtroppo nel mondo ci sono anche i ragazzi cattivi). Nel caso di una vulnerabilità SSRF, ad un utente verrà chiesto di inserire un URL (o un indirizzo IP). La Web App utilizzerà l’input dell’utente per fare a sua volta una richiesta lato Backend. L’SSRF si verificherà nel momento in cui quando l’input non è adeguatamente filtrato o non è filtrato per niente.
Diamo un’occhiata qualche esempio di codice vulnerabile:
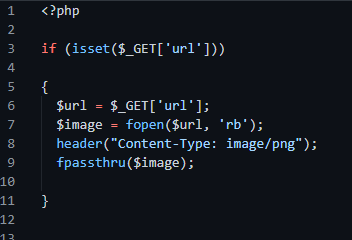
Figura 2 – Esempio Codice vulnerabile PHP
Questo è un esempio di codice PHP che controlla la presenza di informazioni inviate tramite l’URL, in seguito senza eseguire alcun tipo di controllo il codice effettua semplicemente una richiesta all’URL inviata dall’utente. L’ipotetico attaccante ha il pieno controllo di ciò che può eseguire sull’URL, può procedere indisturbato con richieste GET arbitrarie a qualsiasi sito Web esterno, oltre che al backend del server stesso ovviamente.
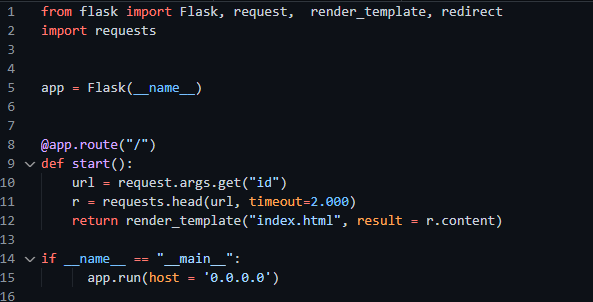
Figura 3 – Esempio codice vulnerabile Python
L’esempio soprastante vi illustra una mini app che fa sostanzialmente la stessa cosa:
- Prende il valore passatole dall’URL
- Fa in seguito una richiesta utilizzata l’URL e mostra all’utente il risultato
Anche in questo caso notiamo che non c’è nessun controllo o filtro sulla richiesta dell’utente al Frontend. Questo è il motivo principale per cui in fase di sviluppo di una web app o di un site dedicato ad altro sarebbe sempre meglio testare molti Payload prima di mettere in produzione il prodotto.
Ok, ma perché SSRF è così pericoloso?
I danni che può causare SSRF dipendono completamente dalla configurazione dei Frontend attaccati e dalla creatività dell’attaccante stesso. Per darci un’idea un po’ più precisa dei suoi effetti ecco alcuni dei rischi più comuni:
- Esposizione dei dati
- L’attaccante tra SSRF può interrogare i servizi interni a cui è possibile accedere solo tramite server attendibili (i frontend). Se la macchina è in uno stato di isolamento (backend) è chiaro che contiene informazioni preziose. Tramite SSRF l’attaccante può aggirare le restrizioni e avere comunque accesso a queste informazioni sensibili.
- Internal Reconnaissance
- Per ovvi motivi spesso si ha l’abitudine di esporre meno possibile all’esterno utilizzando un numero limitato di Frontend, si sceglie di avere più macchine che servono alla comunicazione interna. L’attaccante può utilizzare SSRF per fare una scansione della rete interna. Queste informazioni saranno utili all’attaccante nel momento in cui avrà accesso non autorizzato al Frontend per poi attaccare il resto della rete interna.
- DOS (Denial-Of-Service)
- L’attaccante può utilizzare SSRF per inviare più richieste ai server interni per consumare le loro risorse e larghezza di banda.
CONCLUSIONI
Ci sono svariati metodi di prevenzione basilari come, AllowList e DenyList (limitare le richieste solo alle directory dove sappiamo che ci devono essere richieste, individuare le possibili richieste pericolose nelle URL e fare in modo che vengano sempre bloccate), permettere solo le richieste provenienti da determinati protocolli etc. Questi metodi di prevenzione non sono assolutamente sufficienti, anche dopo aver adottato queste prevenzioni è necessario continuare a monitorare il traffico e cercare di capire come migliorare passo passo la configurazione delle macchine che espongono i vostri servizi. I malintenzionati sono sempre aggiornati sulle prevenzioni adottate e cercano sempre di trovare qualcosa di nuovo per superare le vostre barriere. L’unica via di sentirsi sicuri è dunque quella di continuare a fare ricerca con creatività sulle implementazioni di sicurezza.
Stay Tuned on Technical365!!